大模型
RAG的第一堂课
前言 感觉正在经历被大模型制造的泡沫蒙蔽的时代,很多大V、更多的视频、更多爆炸的信息都在说大模型极为厉害马上就要去替代人类了,很多激进的声音在现在吠气很重的时代空间内充斥。当下时代积极...
前言
感觉正在经历被大模型制造的泡沫蒙蔽的时代,很多大V、更多的视频、更多爆炸的信息都在说大模型极为厉害马上就要去替代人类了,很多激进的声音在现在吠气很重的时代空间内充斥。当下时代积极学习, 充分辨证,学而不思则罔,思而不学则怠。
RAG(Retrieval-Augmented Generation)
可能在很多消息来源中都听到过RAG,有人会读 R.A.G, 有人会读/ræg/, 总之一定听起来很厉害的样子。大模型会有上下文长度限制,如果你需要在一个信息量很大的文档中查找某些重要信息,上下文限制会让任务无法处理,后来就有人提出了RAG,中文意思是:检索增强生成,通过这种技术可以在回答问题前先从大量的“记忆”中先找到相关性最强的信息,再将这些信息一起交给大模型让大模型充分了解知识再去回答,这种准确率将大大增加。
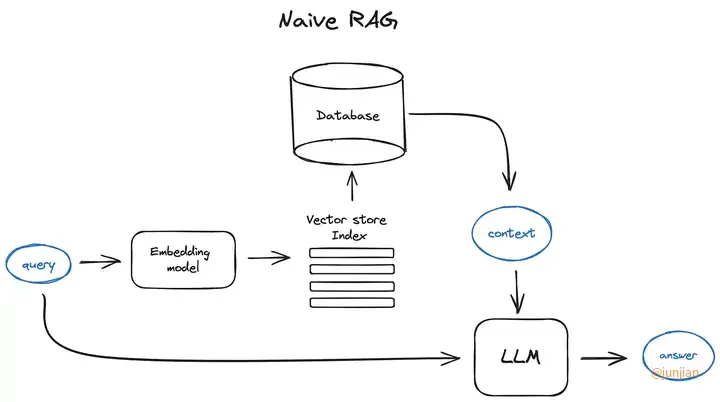
基础知识
文本分片
把一篇长文拆成若干较小、语义完整的文本段(chunks),以便模型能对每一段独立生成向量(embedding), 我们可以通过检索向量的方式找到相似的文本段。
向量.vector
向量是一组数字,用来表示某个对象(如文字、句子、图片)的特征。
它本质上是一种数学表示,用于让机器“理解”语义。
例如:
“苹果” = [0.21, 0.55, -0.12, 0.33, …]
“香蕉” = [0.20, 0.57, -0.11, 0.30, …]
它们看起来像一串数字,但在高维空间中(通常是 768 维、1024 维或更高)代表了语义意义。
重排序
重排序(Re-ranking) 是在初步检索到一批候选文档后, 再使用一个更强大的模型(通常是 cross-encoder) ,对这些候选文档重新打分排序,筛出最相关的内容。
🌰
假设用户问:
“依恋类型理论是谁提出的?”
你的向量数据库检索出 5 条内容:
| 候选文档 | 初始相似度(embedding cosine) |
|---|---|
| A. 鲍尔比提出了依恋理论。 | 0.87 |
| B. 依恋关系是父母与孩子之间的连接。 | 0.85 |
| C. 爱情依恋类型有焦虑型、回避型等。 | 0.84 |
| D. 依恋理论用于解释婴儿行为。 | 0.80 |
| E. 马斯洛提出了需要层次理论。 | 0.79 |
embedding 检索选了 A~C 作为 top-3。
但其实 B、C 只是“相关”,只有 A 是“直接回答”。
这时候我们让一个 re-ranker 模型(如 bge-reranker)
逐一对 (query, doc) 组合进行语义匹配打分,得到更精确的排序:
| 文档 | Re-ranker 分数 |
|---|---|
| A | 0.98 ✅ |
| D | 0.82 |
| C | 0.76 |
| B | 0.72 |
| E | 0.05 |
然后我们重新选 top-2 (A, D),拼进 prompt。
向量相似度算法
| 相似度算法 | 说明 |
|---|---|
| 余弦相似度(Cosine Similarity) | 衡量两个向量方向的相似度,最常见。 |
| 欧几里得距离(L2) | 衡量向量之间的直线距离。 |
| 点积(Dot Product) | 常用于 Transformer 模型中,计算注意力权重。 |
简单实现
# main.py
import chunk
import embed
def get_prompt(question) -> str:
chunks = embed.query_db(question)
prompt = "Please answer user's question according to content\n"
prompt += f"Question: {question}\n"
prompt += f"Context: \n"
for c in chunks:
prompt += f"{c}\n"
prompt += "----------------\n"
return prompt
if __name__ == '__main__':
print(f"begin running {__file__}")
question = "令狐冲痛了嘛?"
print(f"question: {question}\n")
prompt = get_prompt(question)
print(f"Ask:\n{embed.chat_response(prompt=prompt)}")
# embed.py
import chunk
import chromadb
from google import genai
google_client = genai.Client()
EMBEDDING_MODEL = "gemini-embedding-001"
LLM_MODEL = "gemini-2.5-flash"
# 向量数据库
chromadb_client = chromadb.PersistentClient(path="./chromadb_data")
chromadb_collection = chromadb_client.get_or_create_collection(name="expdata")
def embed(text: str, store: bool) -> list[float]:
result = google_client.models.embed_content(
model=EMBEDDING_MODEL,
contents=text,
config= {
"task_type": "RETRIEVAL_DOCUMENT" if store else "RETRIEVAL_QUERY"
}
)
assert result.embeddings
assert result.embeddings[0].values
return result.embeddings[0].values
def create_db() -> None:
for idx, c in enumerate(chunk.get_chunks()):
embedding = embed(c, True)
chromadb_collection.add(
documents=c,
ids=[str(idx)],
embeddings=embedding
)
def query_db(question: str) -> list[str]:
question_embedding = embed(question, False)
reuslt = chromadb_collection.query(
query_embeddings=question_embedding,
n_results=5
)
assert reuslt['documents']
return reuslt['documents'][0]
def chat_response(prompt: str) -> str:
result = google_client.models.generate_content(
model=LLM_MODEL,
contents=prompt
)
return result.text
例子简单演示了一个基础RAG的流程,从文本分片get_chunks -> 嵌入 embed -> 向量搜索 -> LLM。
总结
通过一个简单的例子可以了解RAG的整个工作原理,但通过很多资料也了解到在实际应用中还有很多门道儿存在,比如重排序、记忆等优化手段。如果单纯的步骤还远远达不到公司所能接受的程度。 项目示例代码
参考
(从零写AI RAG 个人知识库) https://www.youtube.com/watch?v=329G_4vJveU @程序员老王